State Machine
2020
A project developed for the Oklahoma Visual Art Coalition's yearly Momentum group show, which showcases work by artists aged 30 and under. I pitched this as a sort of computationally-mediated portrait of Oklahoma.
As a way to consider who we are and what we value, I’ve developed a series of works by taking from various data sources focusing on Oklahomans. One part of this project uses an archive of Oklahoma political advertisements to look at who the state’s political leaders have been and how they’ve represented themselves to appeal to Oklahoman voters. Another work compiles photographs of local 2019 recipients of “Under 30” awards as one way to visualize the faces of those positioned to be future leaders in the state.
I’m interested in how we can think about ourselves as not just globalized citizens subjected to the interconnected, broadening scope of the world after the internet. The work I’ve created for this show considers how contemporary tools might bring insight into localized questions about being an Oklahoman in 2020. They become a portrait of this time and place by looking into the power and ideology that has led us to this moment and will influence our futures.
Political Ads

In the course of working on this project, I learned about the Julian P. Kanter Political Commercial Archive housed at the University of Oklahoma. With the help of the collection’s archivist, I’ve accumulated nearly 4,000 Oklahoma political ads produced across five decades. By implementing machine learning technologies and writing custom software, I’ve created Political Ads — the result of a computer selecting various clips from the archive, splicing them together and assembling that information into a final video.
NextGen Under 30

The 2019 NextGen Under 30 Awards identified 338 young professionals in the state across 17 career categories and serves as the starting point for my work NextGen Under 30. Starting with a list of the winners, I sourced and collected photos of each individual from the internet. The compiled images are a product of how these individuals are branded on social media, either by themselves or their employers, and marketed towards clients, potential employers and their peers.
To create this piece, I’ve implemented software that takes the photographs of these individuals and tries to learn from and then generate its own images of the award winners. This algorithm has been trained using hundreds of thousands of photos to build an understanding of the human face before generating its own portraits. This imagery becomes the basis for animations that move through the set of NextGen Under 30 winners, generating possible alternatives to, connections between, and exaggerations of the faces of these award recipients. I wanted to create this piece specifically for Momentum 2020, an art show which also highlights Oklahomans 30 and under.
Process Notes:
Political Ads
In many ways, working on this project pushed and expanded my typical practice.
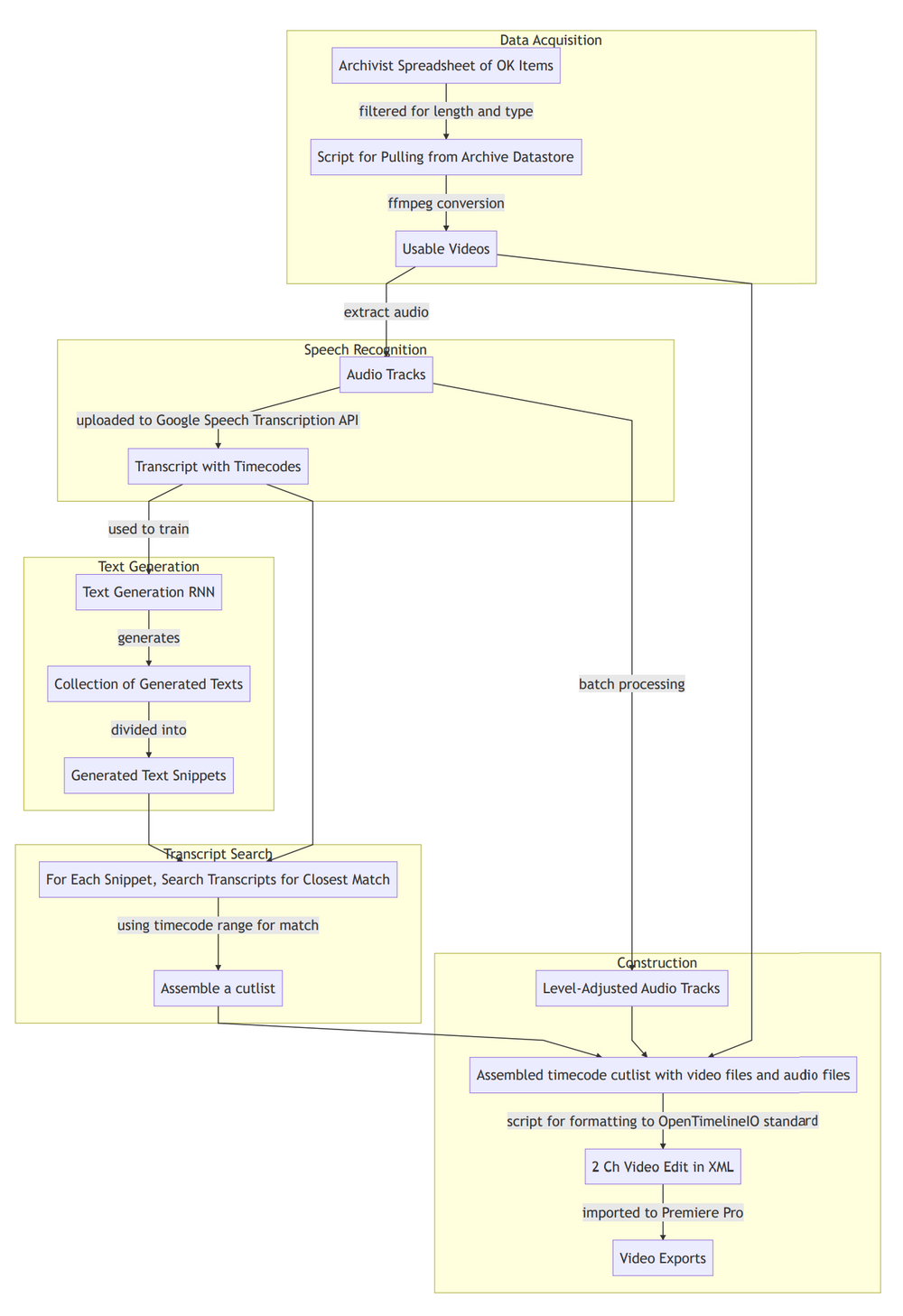
As the data and processes for this piece (along with NextGen Under 30) far exceeded anything I could do on my own computers, it was necessary to utilize computer servers in the cloud. Beyond this, the work also hinged on the cooperation and collaboration of the archive’s archivist Lisa Henry. She was very generous in educating me about the collection, running various queries to find relevant archive materials and allowing me to copy massive amounts of data from their collection which is typically not allowed to leave the facility.
The process for this piece took inspiration from artist Sam Lavigne and his Videogrep software utilized in CSPAN5. In his work, he produces automated edits of videos based on their speech content as taken from closed-captioning. Although I don’t use his software, I reimplement many of its ideas, doing edits not based on real-text searches, but fuzzy-text searches, trying to match computer generated phrases to the archive of video content.
The process for this piece is perhaps the most complicated I’ve worked with, and the broad-strokes are as follows:
NextGen Under 30
The initial labor for this piece began with the highly-tedious process of trying to find a headshot-styled photo of each winner. By going through a spreadsheet of the award winners and running searches using the names, companies and towns associated with them, I tried to find information through Google, LinkedIn, Facebook, Twitter, local newspapers and corporate directories. This was also the strangest part of the process, as I envisioned myself doing a human-scaled version of what large corporations do daily — linking together the disparate digital traces and relationships left behind as residue of a life represented online.
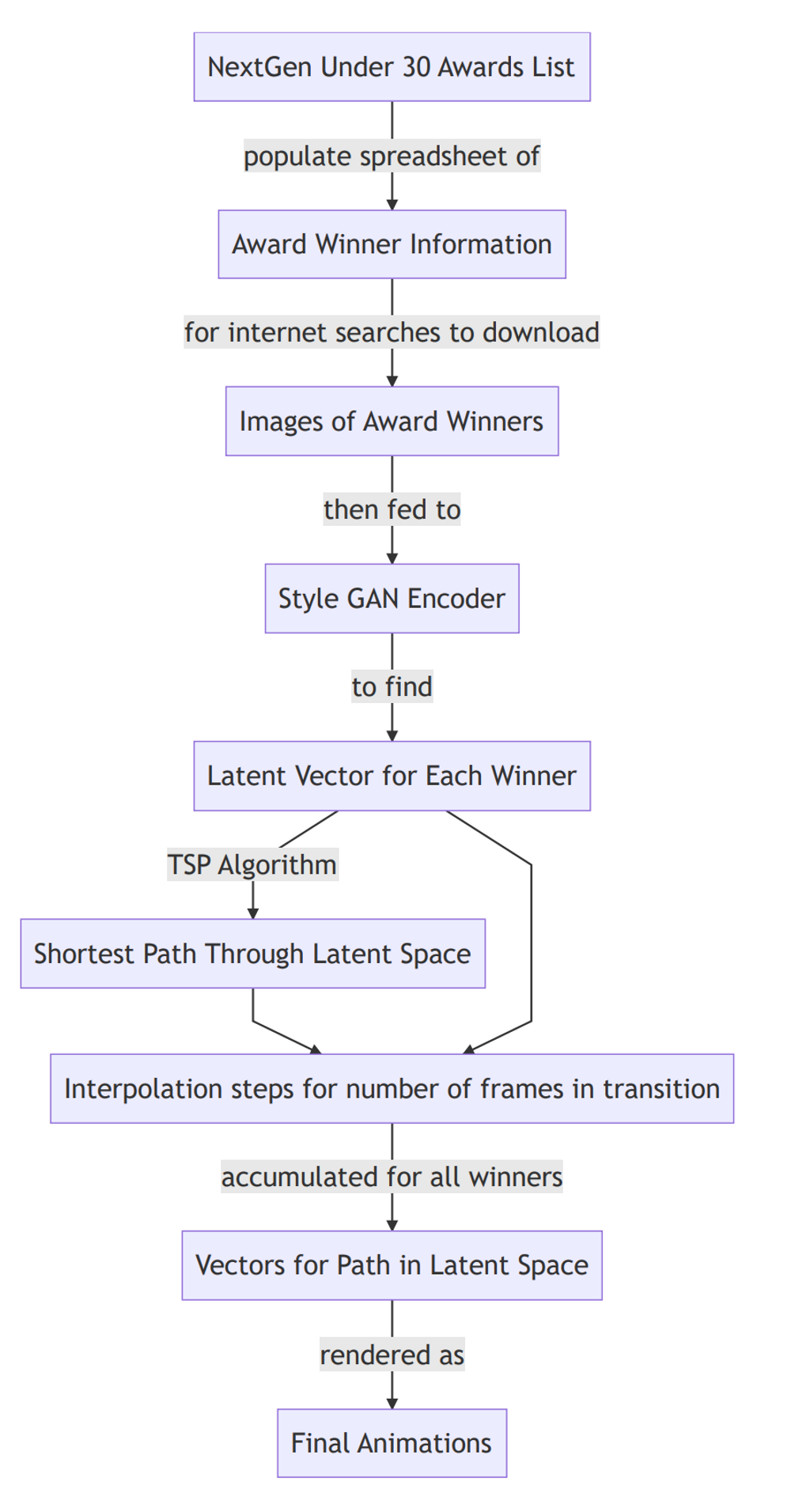
After getting the photos, I utilized software that, using their photo, crops and aligns it, and then searches the latent space of a StyleGAN2 model trained on a dataset of portraits taken from Flickr. After the search, I then have the latent vector that, when fed to the image generation model, will most closely resemble the portrait of the award winner as compared to any other latent vector. This process of “encoding” the photograph as a latent vector is a lengthy one, and this work also required using cloud servers to access their state-of-the-art GPUs for running the machine learning algorithms.

With the intention of travelling from latent vector to latent vector, I then ordered the vectors to minimize the distance traveled to visit each vector only once. In computer science, this problem is called the Travelling Sales Person, and here it allowed me to group “similar” images together, insomuch as images are similar in their latent vector representations.
After finding this order, I calculate the intermediate latent vectors needed to create a path between award winners. I did this at 3 different intervals so that 3 animations could be produced that follow the same path, but do so at different speeds.

The rendered images are then used sequentially as frames for the final animations.